
Revelando el cuello de botella del conteo visual en modelos de visión-lenguaje
Análisis del cuello de botella del conteo visual en modelos de visión-lenguaje: limitaciones actuales y perspectivas para mejorar la precisión en tareas numéricas.
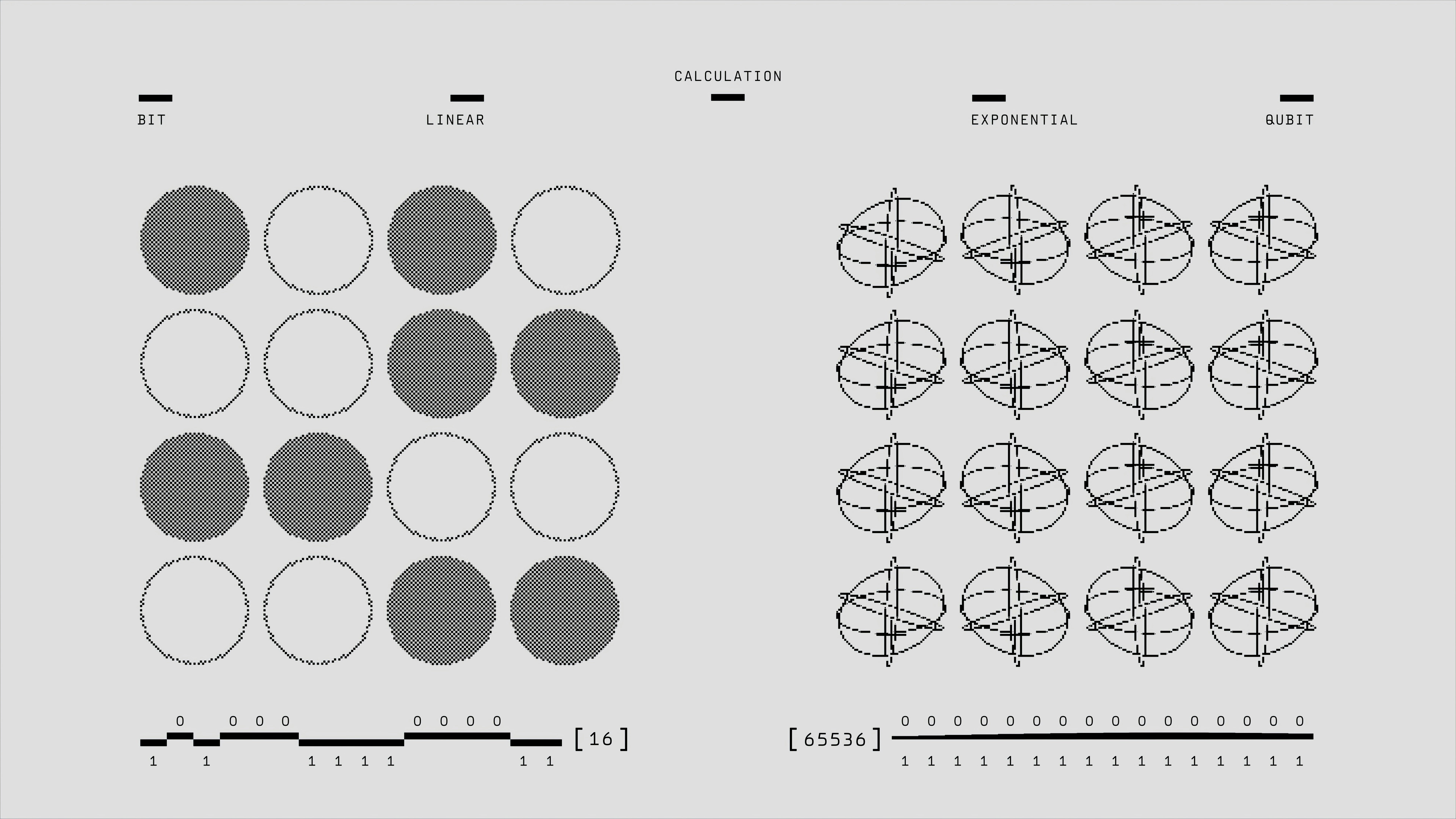
Análisis del cuello de botella del conteo visual en modelos de visión-lenguaje: limitaciones actuales y perspectivas para mejorar la precisión en tareas numéricas.
El razonamiento visual intermedio permite políticas VLA más eficientes. Descubre cómo implementarlo para optimizar resultados.

Descubre SVSR: autoverificación y autocorrección en razonamiento multimodal. Mejora la precisión y robustez de los modelos de IA con este innovador método.
ROVER presenta un enfoque de razonamiento multi-imagen basado en evidencia visual centrada en objetos. Descubre cómo mejora la comprensión de escenas complejas.
<meta name=description content=InterSketch utiliza razonamiento intercalado con bocetos visuales autocorrectivos y recompensa por pasos para generar imágenes mejoradas.>
Doc-CoB utiliza razonamiento visual de cadena de cajas para comprender documentos. Una solución innovadora para el análisis documental automático.
<meta name=description content=CLiViS sinergia lingüístico-visual para razonamiento visual encarnado. Innovación en IA que combina lenguaje y visión para entender y actuar en entornos.>